-1.png)
Hvordan ser et maskinlæringsprosjekt ut hos Inventas?
I Inventas baseres maskinlæringsprosjekter seg på MLOps. Det vil si at vi deler opp et ML-prosjekt i fire faser, som vist i figuren under.
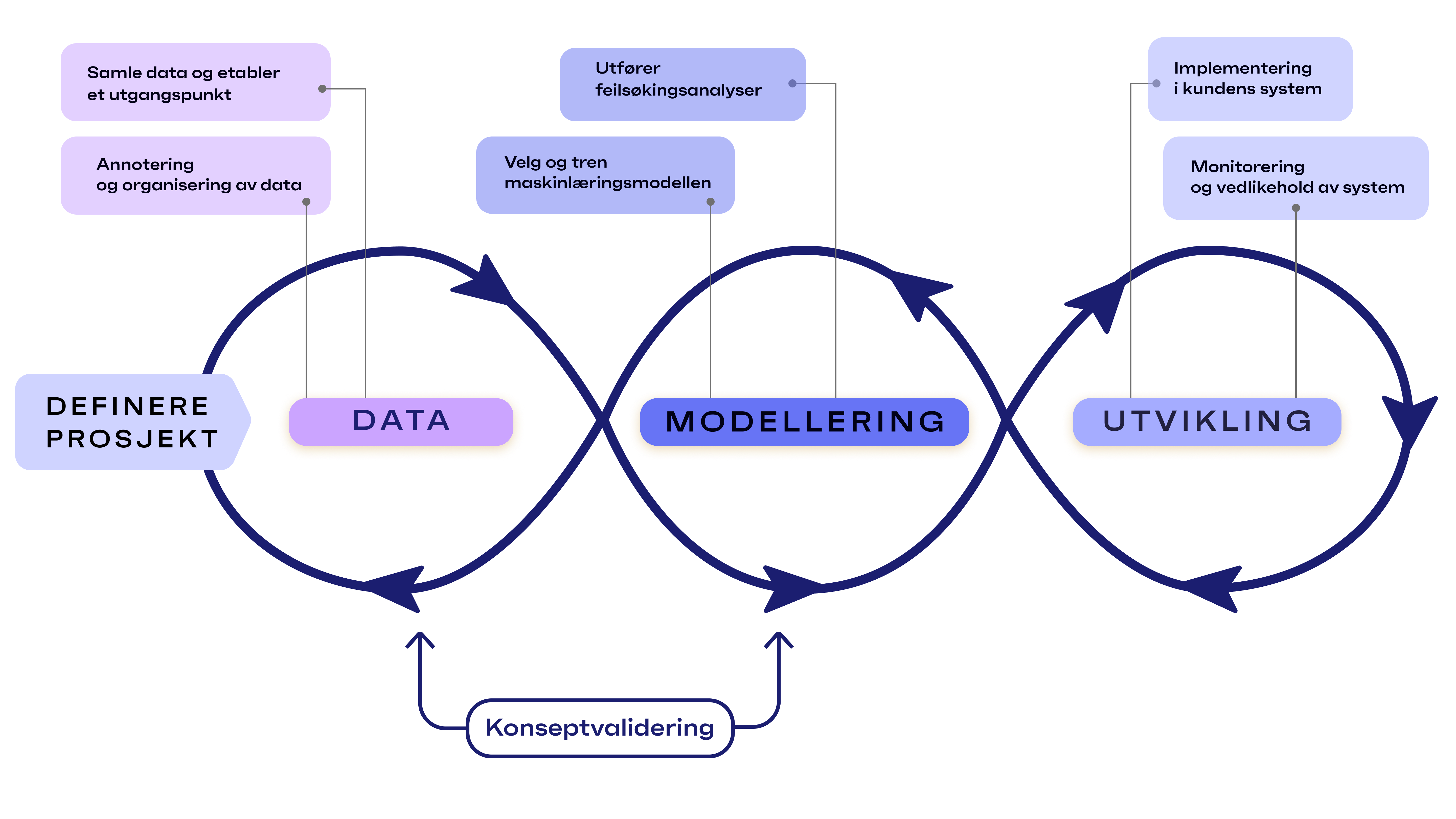
Kartlegge omfang
Dette er innledende fase, hvor prosjektets formål og begrensninger blitt fastsatt. Her setter vi oss ned sammen med deg for å se på problemstillingen, og prøve å komme opp med en mulig løsning.
Samling av datasett
Datamaterialet er en essensiell del av arbeidet med å trene opp modeller. Om du allerede har et datasett tilgjengelig, kan det sendes over til oss for gjennomgang. Om det ikke foreligger et datagrunnlag, vil vi sammen med deg finne best mulig måte å samle inn data av god kvalitet.
Modellering
I denne fasen vil dataene som ble samlet inn i forrige fase bli brukt til å trene modeller for å løse problemstillingen som ble avklart i omfang-fasen. Basert på hvilken type data og problemstilling som skal løses, finnes det er stort utvalg av forskjellige modeller, metoder og teknikker for å få best mulig resultat.
Treningen av modellen påvirkes av flere titalls forskjellige parameterverdier som må velges. Det å trene nye modeller på data er en iterativ prosess, hvor disse parameterverdiene sakte men sikkert blir finjustert.
Som du ser på oversiktsfiguren over, så er det en tilbakekobling fra modelleringsfasen tilbake til datafasen. Dette er fordi det kan vise seg under trening av modeller at datagrunnlaget ikke er stort nok, variert nok, eller inneholder andre former for mangler. I så fall må vi samle inn mer data før vi kan fortsette.
Implementering
Når vi har funnet en god, robust modell, vil vi i denne fasen implementere modellen inn i dine systemer. Her er det naturlig med en innføringsfase, så vi kan se hvordan systemet oppfører seg i virkeligheten.
I oversiktsfiguren er det også i denne fasen en tilbakekobling til forrige fase. Under test hos kunden kan det igjen bli oppdaget ukjente problemstillinger vi ikke var klar over tidligere. Dette kan igjen føre til at vi må samle inn mer data, trene nye modeller, og implementere systemet på nytt.
Hvilke faktorer spiller inn på prisen av maskinlæring?
Det er praktisk talt umulig å gi et generisk anslag på hva prosjektet vil koste, da det kommer helt an på hvor kompleks oppgaven er. Som ofte når man driver med produktutvikling, er svaret: «Det kommer an på». Det er likevel noen typiske aspekter som er med på å bestemme prisen.
Datagrunnlag
Datagrunnlaget er et av de viktigste elementene av et maskinlæringssystem. Det er derfor viktig at dette er av en viss størrelse og kvalitet. Noen ganger kan man klare seg med et par hundre bilder, eller ganske små datasett. I et proof-of-concept eller konseptvalideringsprosjekt, vil vi typisk bruke et mindre datasett. I større prosjekter med vanskelige problemstillinger kan det være nødvendig med et større datagrunnlag.
I enkelte situasjoner er det ikke mulig å samle inn nok data. Med lite data er det vanskelig å få gode resultater, og modellene er samtidig utsatt for overtrening (når modellen er for tilpasset de spesifikke eksemplene at den ikke klarer å generalisere videre når det introduseres selv de minste avvik).
Det finnes teknikker for å trene modeller med lite data, men dette vil kreve mer tid til utvikling og eksperimentering. I tillegg er det vanskelig å få gode resultater med dårlige data. Eksempler er bilder tatt ved dårlige lysforhold, bilder tatt fra avstand, eller generelt data med mye støy.
Om dataene ligger spredt rundt på forskjellige lokasjoner, ligger i en stor database med mye annen data, eller består av en blanding av god og dårlig data, må vi rydde dataene først og hente ut det vi trenger. Det varierer veldig fra prosjekt til prosjekt hvorvidt dette er enkelt eller tidkrevende.
Annoteringer
Mye data i seg selv er ikke nok. Det er også nødvendig med sannhetsmarkeringer for at modeller skal kunne lære av dataene. Dette omtales ofte for annotering, og kan bestå av hvilken klasse (type ting, f.eks. en katt)som vises på et bilde, eller hvor i bildet et objekt befinner seg (tegnes ofte som en rød boks rundt objektet).
Noen typer annotering som for eksempel medisinske data, krever mye kunnskap. Her er det gjerne nødvendig med flere års utdannelse bare for å tolke bildene, og det kan derfor være utfordrende å samle inn store mengder av slik annotert data.
For å lage gode modeller er det nødvendig med mye annotert data, og annotering kan bli en av de største utgiftene på et prosjekt. Kvaliteten på annotering kan i stor grad påvirke resultatet til modellen din. I tilfelle annoterte data mangler, blir det nødt til å innhentes. Vi kan gjøre dette selv, eller bistå deg med å samle inn data på en fornuftig måte.
Problemstilling
Ved hvert prosjekt må vi sammen ta en vurdering over hvor vanskelig problemstillingen er, og hvorvidt den faktisk er gjennomførbar. Problemstillinger som er mer krevende, tar naturlig nok også mer tid å gjennomføre. Selv om maskinlæring ligger under paraplyen kunstig intelligens, er det viktig å passe på at man ikke antropomorfiserer modeller.
«Antropomorfisme er en opprinnelig gresk betegnelse på tilfeller der man overfører menneskelige egenskaper til ikke-mennesker, som guder, dyr, fantasifigurer, naturfenomener eller gjenstander» – Store Norske Leksikon
Stilles det strenge krav til systemets ytelse, kan dette også føre til ekstra kostnader. Krever du for eksempel ekstra høy nøyaktighet, kan det føre til at den iterative prosessen med å finne best mulig modell vil ta lengre tid. Er det et krav at systemet skal kunne gi en prediksjon innen veldig kort tid, må hele prosessen optimaliseres. Er det krav til lavt strømbruk, for eksempel om systemet skal kjøre på en edge-device, kan dette påvirke og begrense utvalget av hvilke modeller vi kan bruke.
Leveranse
Hva du ønsker at vi skal levere, spiller også inn. Her er det naturlig at software og ferdig trente modeller er en del av leveransen, men vi kan levere en total løsning bestående av et brukergrensesnitt kjørende på en datamaskin, en app for telefon, eller et fysisk produkt hvor løsningen er sentral.
For å kjøre kunstig intelligens-/maskinlæringssystemer, trenger du kraftige datamaskiner med grafikkort (GPU). Vi kan også levere dette, eller sette opp en skyløsning. Vi har også lang tids erfaring med systemer basert på FPGA eller mikrokontrollere.
Lyst til å vite mer?
Ta kontakt med oss, så svarer vi gjerne på mer konkrete spørsmål om ditt maskinlæringsprosjekt.
